
Update infromation:
2024/05/01 JST License information was updated.
2022/10/26 JST Terrain22 (Global GeoTIFF) data was added.
2022/06/04 JST This website opened. The polygon data was published.
The contents of this website are subject to change without notice.
General Information
This site is a data publication site for data related to the following paper:
Citation
For the polygon data attached to Iwahashi and Yamazaki (2022):
Iwahashi, J., Yamazaki, D. (2022) Global polygons for terrain classification divided into uniform slopes and basins. Prog Earth Planet Sci 9, 33. https://doi.org/10.1186/s40645-022-00487-2
For Terrain22:
In addition to the above paper, please cite Terrain22 and this URL.
For example, "we used Terrain22, which is publicly available from https://gisstar.gsi.go.jp/terrain2021/ as a derivative of the data by Iwahashi and Yamazaki (2022)."
License
This work was originally supported by JSPS KAKENHI Grant Number JP18H00769.
Based on the concept of JSPS KAKENHI which encourages open access, we believe the data published on this site is licensed under a Creative Commons CC-BY 4.0.
When you use the data in your paper or presentation or product, please be sure to follow the above citation.
Materials
DEM (Digital Elevation Model) MERIT DEM v1.0.3 (based on Yamazaki et al., 2017 MERIT DEM) was used as the primary material for these datasets.
Masking data of NoData For lakes, lake polygons from HydroLAKES (Messager et al., 2016) were used. For major rivers and brackish lakes, the Code2 major rivers and water sections extracted from the OSM Water Layer was used (OSM Water Layer is available for download on the IIS U-Tokyo website). Please note that these mask data were used as masks to minimize errors in areas where the slopes change rapidly and do not necessarily reflect the actual extent of the land and water areas.
Basin data The unit catchment polygons of MERIT-Basins (Lin et al., 2019 website) were used as thematic data for segmentation.
Noise area Polygon data of noise regions (self-made by manual interpretation, mainly for stripe noise and ice sheets) were used as thematic data for segmentation.
Terrain measurements
Table 1
| Attribute |
Usage |
Calculation method |
Description |
| lnSLOPE |
Segmentation and classification |
ln(SLOPE + 1)
SLOPE: slope gradient (degrees) calculated from the 90-m DEM interpolated by the bilinear option |
SLOPE was calculated within 3 by 3 cells windows, using QGIS 3.14, by the Horns method |
| lnHAND |
Segmentation and classification |
ln(HAND + 1)
HAND: Height Above the Nearest Drainage (m) |
HAND was calculated by the method of Yamazaki et al. (2012) and Yamazaki et al. (2019). |
| TEXTURE |
Classification |
Density within a 10-cell radius of pits and peaks obtained by the difference between the Original DEM from the 3x3 median filtered DEM.
Original DEM: the 90-m DEM interpolated by the nearest-neighbour option |
The surface texture of Iwahashi and Pike (2007). TEXTURE was calculated by the "terrain surface texture" tool of SAGA (Conrad, 2012a) in QGIS 3.4 (Threshold: 5-m, radius: 10-cells, no distance weighting) |
| CONVEXITY |
Supplementary |
Density within a 10-cell radius of convex points obtained by processing the DEM with a 3x3 Laplacian filter.
Original DEM: the 90-m DEM interpolated by the nearest-neighbour option |
The local convexity of Iwahashi and Pike (2007). CONVEXITY was calculated by the "terrain surface convexity" tool of SAGA (Conrad, 2012b) in QGIS 3.4 (Threshold: 1-m, radius: 10-cells, no distance weighting) |
| Sinks |
Supplementary |
Sinks is the following region:
((Filled DEM) - (Original DEM)) > 0
Original DEM: the 90-m DEM interpolated by the bilinear option |
Filled DEM was calculated by the "Fill Sinks (Wang & Liu)" (Wang and Liu, 2006) tool of SAGA in QGIS 3.4 |
Data partitioning
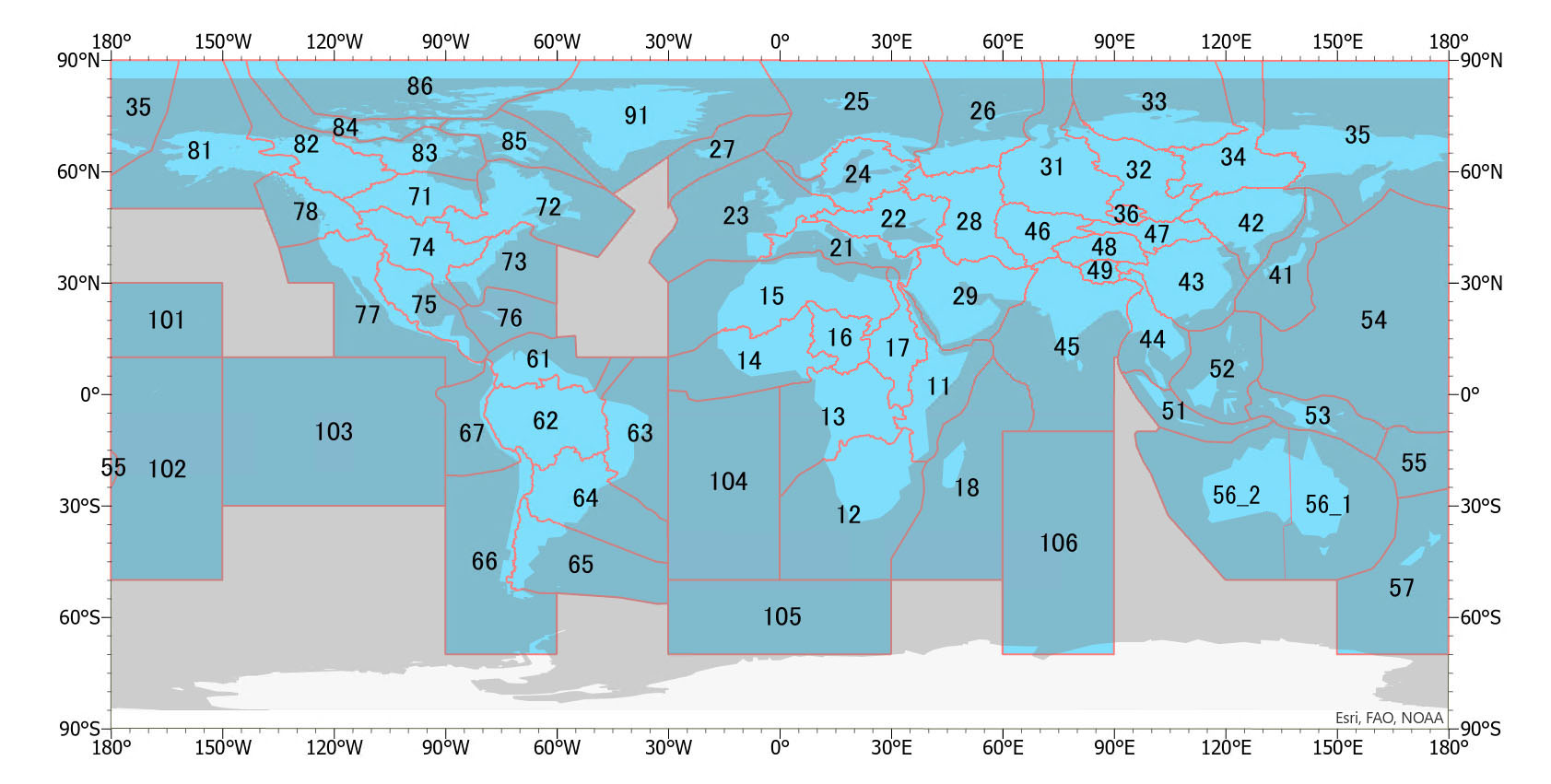
The polygon data sets are provided for each of MERIT-Basin's major hydrological boundaries (Lin et al., 2019) and boundaries drawn in the sea (below). The numbers 11 to 91 coincide with the basin numbers of MERIT-Basin (Lin et al., 2019).
Segmentation and classification
We used the multiresolution segmentation tool of eCognition v10 (Trimble) for segmentation. The unit catchment polygons from MERIT-Basins (Lin et al., 2019) were superimposed as a thematic layer and designed so that slopes of similar shape (defined by lnSLOPE and lnHAND) are divided by the ridge line of the catchment area. Noise areas (if present) were also superimposed.
The k-means clustering tool of SPSS v26 was used for the classification.
For more information, please check Iwahashi and Yamazaki (2022).
Polygon data attached to Iwahashi and Yamazaki (2022): released 2022/06/04 JST
Download
Please see the figure above for the index numbers.
Polygon dataset:
11 (391MB, unzipped 2.13GB)
12 (495MB, unzipped 2.69GB)
13 (603MB, unzipped 3.32GB)
14 (454MB, unzipped 2.54GB)
15 (749MB, unzipped 4.20GB)
16 (256MB, unzipped 1.43GB)
17 (340MB, unzipped 1.90GB)
18 (79.6MB, unzipped 436MB)
21 (176MB, unzipped 969MB)
22 (311MB, unzipped 1.68GB)
23 (210MB, unzipped 1.13GB)
24 (218MB, unzipped 1.18GB)
25 (91.6MB, unzipped 494MB)
26 (131MB, unzipped 731MB)
27 (15.2MB, unzipped 82.9MB)
28 (387MB, unzipped 2.12GB)
29 (680MB, unzipped 3.76GB)
31 (388MB, unzipped 2.15GB)
32 (358MB, unzipped 1.93GB)
33 (152MB, unzipped 833MB)
34 (346MB, unzipped 1.86GB)
35 (392MB, unzipped 2.08GB)
36 (39.4MB, unzipped 217MB)
41 (64.3MB, unzipped 354MB)
42 (394MB, unzipped 2.12GB)
43 (580MB, unzipped 3.14GB)
44 (289MB, unzipped 1.56GB)
45 (553MB, unzipped 3.02GB)
46 (255MB, unzipped 1.41GB)
47 (175MB, unzipped 974MB)
48 (198MB, unzipped 1.08GB)
49 (79.2MB, unzipped 424MB)
51 (87.3MB, unzipped 490MB)
52 (160MB, unzipped 890MB)
53 (123MB, unzipped 687MB)
54 (730KB, unzipped 3.80MB)
55 (7.3MB, unzipped 40.6MB)
56_1 (350MB, unzipped 1.99GB)
56_2 (481MB, unzipped 2.72GB)
57 (38.6MB, unzipped 210MB)
61 (248MB, unzipped 1.35GB)
62 (811MB, unzipped 4.48GB)
63 (274MB, unzipped 1.48GB)
64 (407MB, unzipped 2.25GB)
65 (176MB, unzipped 978MB)
66 (150MB, unzipped 812MB)
67 (69.9MB, unzipped 384MB)
71 (236MB, unzipped 1.28GB)
72 (366MB, unzipped 1.92GB)
73 (130MB, unzipped 735MB)
74 (408MB, unzipped 2.23GB)
75 (274MB, unzipped 1.49GB)
76 (27.6MB, unzipped 154MB)
77 (346MB, unzipped 1.88GB)
78 (201MB, unzipped 1.05GB)
81 (246MB, unzipped 1.30GB)
82 (249MB, unzipped 1.33GB)
83 (140MB, unzipped 769MB)
84 (44.2MB, unzipped 238MB)
85 (77.2MB, unzipped 419MB)
86 (61.3MB, unzipped 333MB)
91 (244MB, unzipped 1.37GB)
101 (2.13MB, unzipped 11.8MB)
102 (946KB, unzipped 5MB)
103 (743KB, unzipped 4.1MB)
104 (68.8KB, unzipped 347KB)
105 (70.6KB, unzipped 350KB)
106 (1.25MB, unzipped 6.83MB)
* 56_1 and 56_2 are the same basin, but due to the amount of data, the segmentation was done in two parts divided by boundaries of unit catchments. The clustering was done in a lumped manner.
- Properties of the polygon data (shapefile dataset, Poly_XX) XX: the index number
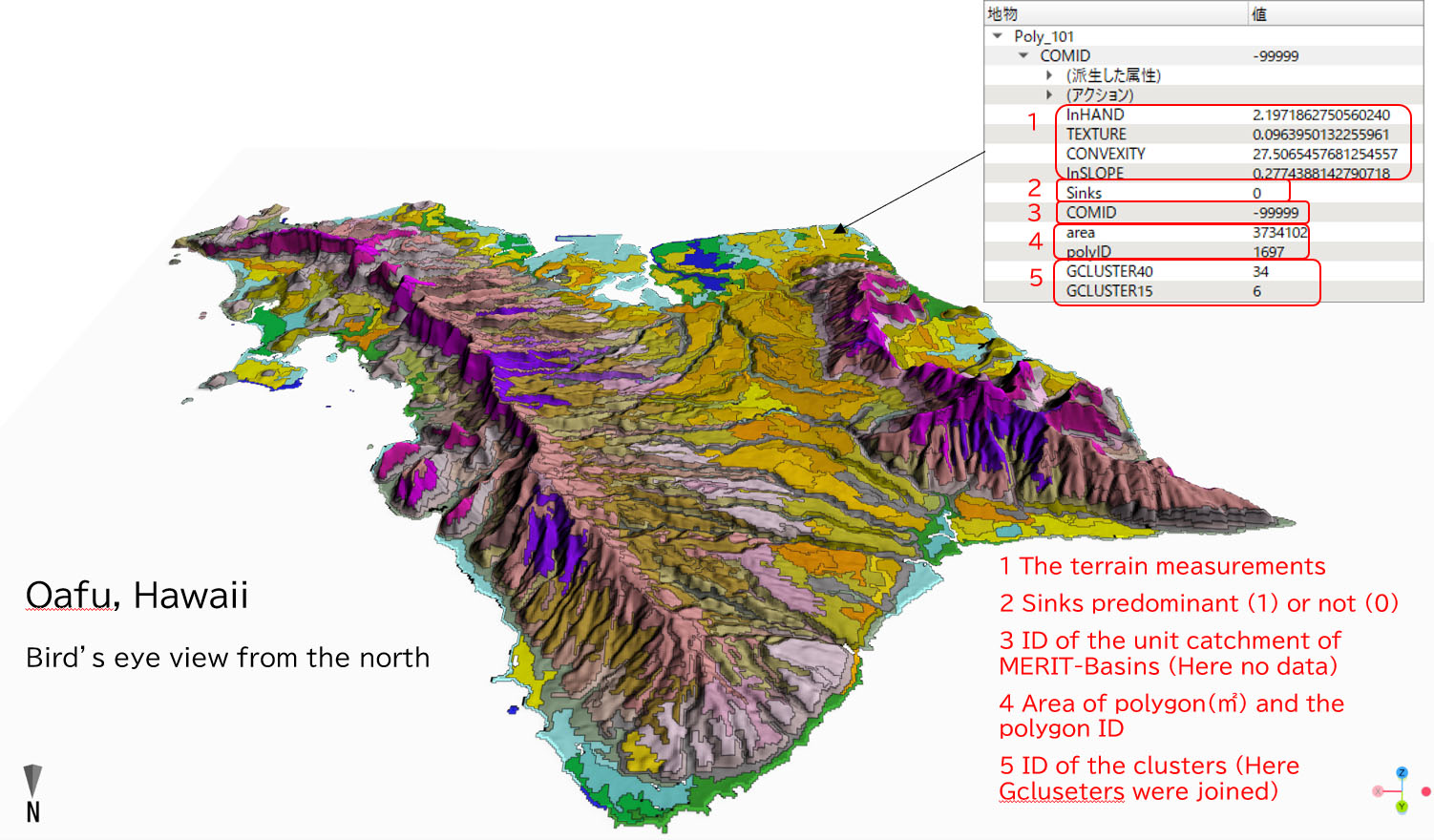
polyID: ID number for each polygon
lnSLOPE(calculated as in Table 1): average value
lnHAND(calculated as in Table 1): average value
TEXTURE(calculated as in Table 1): average value
CONVEXITY(calculated as in Table 1): average value
Sinks(calculated as in Table 1): (1) The majority of the area within a polygon is sinks. (0) The majority of the area within a polygon is not sinks.
Noise(manual interpretation; datasets with apparent noise only): (0) There is no apparent noise or ice sheet. (1) There is apparent noise on CONVEXITY. (2) There is apparent noise on TEXTURE and CONVEXITY. (3) Apparent ice sheet. (4) There is apparent noise on TEXTURE. (5) There is apparent noise on lnSLOPE. (6) There is apparent noise on lnSLOPE, TEXTURE, and CONVEXITY. * (0) to (2) are found in a wide range of areas; (3) is found in the polar regions; (4) to (6) are found only in desert areas.
COMID: ID number for each unit catchment of MERIT-Basin (Lin et al., 2019). Polygons with '-99999' are the regions which MERIT-Basin does not cover.
- Properties of the cluster file (regional or global cluster; dBASE IV, Cluster_XX or GlobalCluster_XX)
polyID: ID number for each polygon
ZlnSLOPE: standardized lnSLOPE. Noise areas (2) to (6) are not included.
ZlnHAND: standardized lnHAND. Noise areas (2) to (6) are not included.
Ztexture: standardized TEXTURE. Noise areas (2) to (6) are not included.
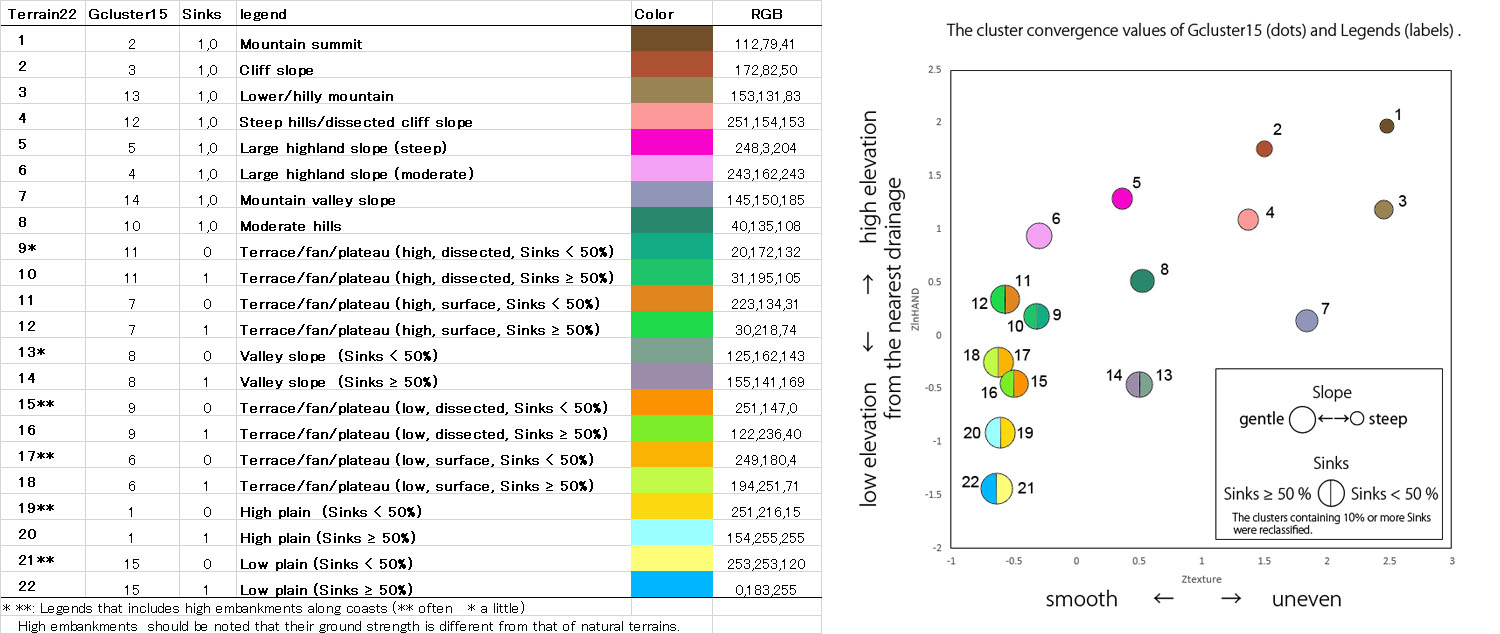
Cluster15, Cluster40: Cluster number by k-means clustering of 15 and 40 categories using standardized lnSLOPE, lnHAND and TEXTURE of the basin with each polygon area as the weight. The cluster number (1-15 or 1-40) is not common to other basins. A map using this data cannot be merged with different basins. Noise areas (2) to (6) are not included. On some small islands, Cluster40 was omitted.
Gcluster15, Gcluster40: Cluster number by k-means clustering of 15 and 40 categories using standardized lnSLOPE, lnHAND and TEXTURE of the global data with each polygon area as the weight. The cluster number (1-15 or 1-40) is common to other basins. A map using this data can be merged with different basins. Noise areas (2) to (6) are not included.
- Properties of the cluster convergence values (CSV, XX_convergence_values_cluster15, XX_convergence_values_cluster40, Global_convergence_values_cluster15, Global_convergence_values_cluster40)
Convergence values for each clustering of ZlnSLOPE, ZlnHAND, Ztexture.
Usage of the dataset
- Joining with the cluster file: The cluster file (dBASE IV; Cluster_XX, GlobalCluster_XX) can be joined with the shapefile dataset (Poly_XX) by polyID using GIS software.
- Grouping the cluster: If you feel that the number of clusters (e.g. 40) is too large, you can consider grouping them by your own customized method. Please find ideas for groupings in Iwahashi and Yamazaki (2022).
- Use of topographic measurements: you can create an original classification map using attributes within the polygons.
- Partial reclassification: Sinks can be used to re-classify plains.In areas where CONVEXITY does not contain noise, its use may enable you to re-classify intermediate slopes.
- Use of COMID: COMID (Lin et al., 2019) can be used as a key to join data on the upstream and downstream locations of unit catchments (additional river data of Lin et al. (2019) is needed). The relationship between upstream and downstream in the same unit catchment can probably be determined by the value of lnHAND.
Notes
- The DEM reflects the topography at the time of measurement. Due to the nature of MERIT DEM, unevenness may remain in densely built-up areas. Therefore, the classification results are not likely to be the expected ground proxies for man-made altered areas such as reclaimed land or cut-and-fill areas, and areas of dense high-rise buildings.
- Since the Noise areas were designated visually, there is a possibility that there may be some oversight or overestimation.
- In some areas of brackish lakes and large rivers, the center-line may not be NoDATA, but thin polygons. This is due to the OpenStreetMap used to extract these areas. Since the areas are very small, they do not have obvious influence on clustering, but sometimes they may need to be removed before use.
- There are often small polygons at the confluences of valleys.
- Terrestrial lands formed after the measurement period of the source DEM of MERIT have an elevation of 0. Therefore, they are classified into the same cluster as low plains. We changed the cluster number to 0 where we noticed it, but some may still exist in the dataset.
- Small lakes that are not included in Hydro LAKES (Messager et al. 2016) and OSM Water Layer (Yamazaki et al. 2017) are classified in the same cluster as low plains.
- If you find errors in the data, please contact the first author.
Terrain22 (Global GeoTIFF): released 2022/10/26 JST
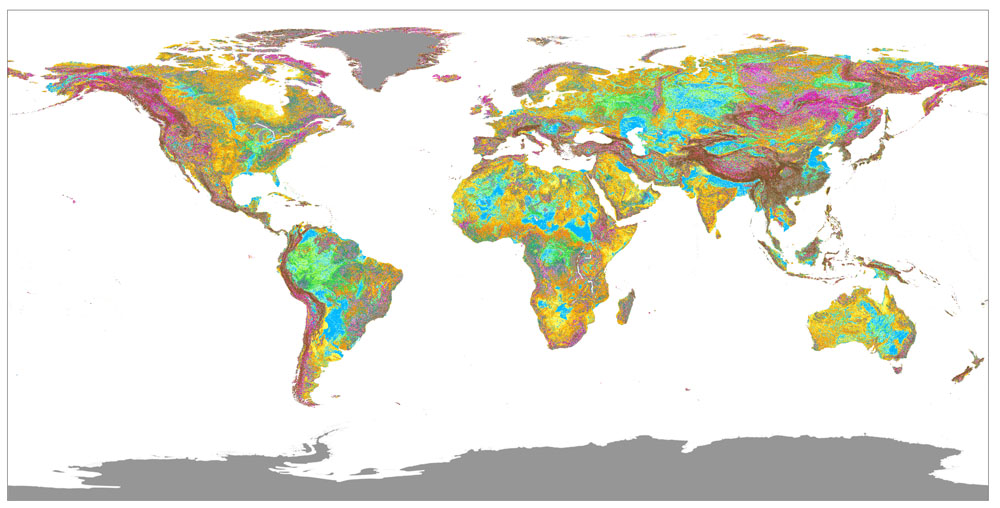
Based on Gcluster15 (in addition, the clusters with more than 10% polygons of Sinks (1) were subdivided), terrain classification maps were constructed and published on GeoTIFF as Terrain22. Terrain22 maps can be joinable and allow global terrain observation in a 3-second-arc grid, WGS84, GeoTIFF format.
Terrain22 is a processed product of the polygon data of Iwahashi and Yamazaki (2022). When citing Terrain22, please cite Iwahashi and Yamazaki (2022) and also include this URL and specify Terrain22.
- There is a gap of about 1 cell at the seam with the adjacent GeoTIFF.
- Other precautions for data use are the same as those for "Notes" above.
- Please note that Terrain22 is just one of many examples that can be constructed from the polygon data. If you do not need to join different Basins, the method constructing terrain groups using regional clusters such as Cluster40 will probably give better results. (please check Iwahashi and Yamazaki 2022, Chapter "The regional clusters")
 Data partitioning is the same with the polygon dataset.
Data partitioning is the same with the polygon dataset.
Download
File size is 422 KB (105) to 103 MB (62).
GeoTIFF:
11
12
13
14
15
16
17
18
21
22
23
24
25
26
27
28
29
31
32
33
34
35
36
41
42
43
44
45
46
47
48
49
51
52
53
54
55
56_1
56_2
57
61
62
63
64
65
66
67
71
72
73
74
75
76
77
78
81
82
83
84
85
86
91
101
102
103
104
105
106
QGIS qml (style)
color settings for QGIS
References
Conrad O (2012a) Module Terrain Surface Texture / SAGA-GIS Module Library Documentation (v2.2.5). http://www.saga-gis.org/saga_tool_doc/2.2.5/ta_morphometry_20.html
Conrad O (2012b) Module Terrain Surface Convexity / SAGA-GIS Module Library Documentation (v2.2.5). http://www.saga-gis.org/saga_tool_doc/2.2.5/ta_morphometry_20.html
Iwahashi J, Pike RJ (2007) Automated classifications of topography from DEMs by an unsupervised nested-means algorithm and a three-part geometric signature, Geomorphology, 86, 409-440. https://doi.org/10.1016/j.geomorph.2006.09.012
Data download siteIwahashi J, Kamiya I, Matsuoka M and Yamazaki D (2018) Global terrain classification using 280 m DEMs: segmentation, clustering, and reclassification. Progress in Earth and Planetary Science, 5:1. https://doi.org/10.1186/s40645-017-0157-2
Data download siteIwahashi J, Yamazaki D, Nakano T, Endo R (2021) Classification of topography for ground vulnerability assessment of alluvial plains and mountains of Japan using 30 m DEM. Progress in Earth and Planetary Science, 8:3. https://doi.org/10.1186/s40645-020-00398-0
Data download siteLin P, Pan M, Beck HE, Yang Y, Yamazaki D, Frasson R, David CH, Durand M, Pavelsky TM, Allen GH, Gleason CJ, Wood EF (2019) Global reconstruction of naturalized river flows at 2.94 million reaches. Water Resources Research https://doi.org/10.1029/2019WR025287
Messager ML, Lehner B, Grill G, Nedeva I, Schmitt O (2016) Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nature Communications: 13603. https://doi.org/10.1038/ncomms13603
Wang L, Liu H (2006) An efficient method for identifying and filling surface depressions in digital elevation models for hydrologic analysis and modelling. International Journal of Geographical Information Science, Vol. 20, No. 2, 193-213.
Yamazaki D, Baugh CA, Bates PD, Kanae S, Alsdorf DE, Oki T (2012) Adjustment of a spaceborne DEM for use in floodplain hydrodynamic modeling. Journal of Hydrology, Vol. 436-437, 81-91.
Yamazaki D, Ikeshima D, Tawatari R, Yamaguchi T, O'Loughlin F, Neal JC, Sampson CC, Kanae S, Bates PD (2017) A high accuracy map of global terrain elevations, Geophysical Research Letters, vol.44, pp.5844-5853, https://doi.org/10.1002/2017GL072874
Yamazaki D, Ikeshima D, Sosa J, Bates PD, Allen GH, Pavelsky TM (2019) MERIT Hydro: a high‐resolution global hydrography map based on latest topography dataset. Water Resources Research, 55,5053–5073. https://doi.org/10.1029/2019WR024873